







































OpenAI has unveiled its latest generative AI model, GPT-4o, with the “o” signifying its omni capabilities in handling text, speech, and video. This groundbreaking model is set to be deployed progressively across the company’s developer and consumer-facing products over the next few weeks.
Mira Murati, OpenAI’s CTO, announced that GPT-4o offers “GPT-4-level” intelligence but enhances performance across multiple modalities and media. GPT-4o represents a significant leap forward in natural human-computer interaction, as it can process and generate inputs and outputs in any combination of text, audio, and images in real time. The model is designed to respond to audio inputs in as little as 232 milliseconds, with an average response time of 320 milliseconds, closely mimicking human conversational speed.
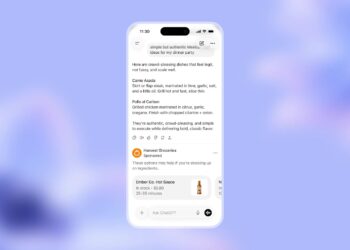
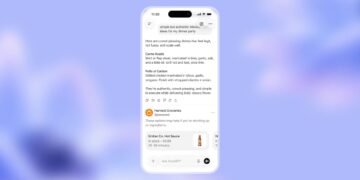
Starting today, GPT-4o’s text and image capabilities are being rolled out in ChatGPT. OpenAI is making GPT-4o available in the free tier and to Plus users, who will benefit from up to five times higher message limits. Additionally, a new version of Voice Mode powered by GPT-4o will enter alpha testing within ChatGPT Plus in the coming weeks.
The new model is trained end-to-end across text, vision, and audio, allowing all inputs and outputs to be managed by a unified neural network. This integrated approach ensures more seamless interactions and superior overall performance. On traditional benchmarks, GPT-4o matches the performance of GPT-4 Turbo in text reasoning and coding intelligence while setting new standards for multilingual, audio, and visual capabilities.
Additionally, GPT-4o is faster and 50% cheaper in API usage compared to its predecessors. This efficiency, combined with its enhanced capabilities, marks a significant advancement in the field of artificial intelligence. Murati noted that while GPT-4o is a substantial development, OpenAI is just beginning to explore its full potential and limitations.
As the first model to combine text, vision, and audio capabilities, GPT-4o is expected to revolutionize how users interact with AI. Its iterative rollout will provide valuable insights into its application and performance in real-world scenarios, paving the way for more natural and efficient AI interactions across various media formats.